

Why Use Web Services?
If you have a high-volume need for court information, CourtTrax Web Services allows automated machine-to-machine data exchange over the Internet, so that your applications and data bases can automatically and efficiently search, retrieve, and integrate CourtTrax's real-time data.
The CourtTrax Web Services, known as I-Tap (Integrated Transaction Automation Process), offers our business partners a clearly defined programming and data interface, employing XML data transmitted over HTTP.
This allows our partners' automated computer systems to interface directly with our proven court search functionality. The Itap service functions as a back-end component of our clients' systems.
After retrieving data from us, the client is free to use, store, display, or recombine the received data with other available data to meet their specific business needs. We offer a variety of retrieval options, including both full sematic XML data and XHTML renderings of the data, for our clients to choose the integration path that best meets their own requirements for end-to-end automated court search.
Who needs real-time court data?
For example, I-Tap provides a strategic competitive advantage when embedding our services in a title examining
application, or financial services applications like automated due diligence checks.
I-Tap can also easily be embedded in insurance applicant screening programs, or other on-line business information services. There are wide range of business processes where CourtTrax Web Services can immediately add value.
How Web Services Work
With the I-Tap web service, your system can submit a machine-generated search command consisting of a URL plus a small XML input document, to launch a court information search and receive an XML or XHTML response containing search results.
Each I-Tap connection meets precise specifications for court records retrieval. The query URL specifies the search space — the target courts, the type of search, and the case type — while any additional specific parameters such as identifying personal characteristics when searching for a person are supplied in the input document.
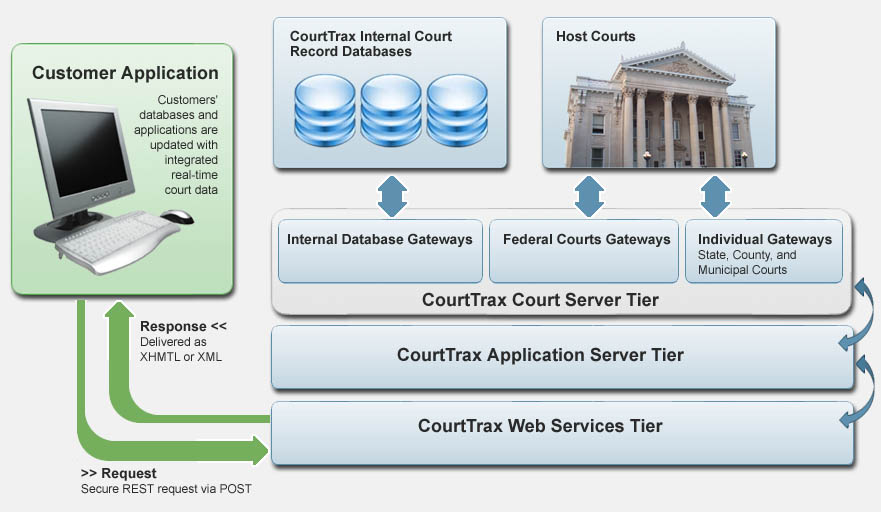
Your system posts a request to our web server, where the request is directed down through our stack to our Court Server tier, where the request is dispatched to the Courts gateway servers.
The court data is retrieved by the gateway server then processed back up the stack where it is sent back as a response to your request. You have the option to retrieve search responses in one of two forms — either as an XML file or as a pre-configured XHTML file. Record output is easily mapped to HR-XML, LegalXML, or to your custom specifications.
Industry-Standard Technology
CourtTrax web services use second-generation Representational State Transfer (REST) technology, a software architectural style for distributed systems, as a simple interface using XML over HTTP without additional messaging layers.
In addition to its ease-of-use, REST provides improved response times and server loading characteristics, improved scalability, and less client-side and vendor software. It also provides better long-term compatibility and evolvability characteristics. It has also allowed us to implement reliable messaging in our protocol that enables seamless client recovery from temporary internet communication hiccups, no matter when they might occur.
REST Assured
Because of this scalability and reliability, REST technology is currently used by industry leaders such as
Amazon, eBay, Netflix, Twitter, and others to automate information exchange with their business
partners.
Enterprise Data Model
Our XML result data conforms to the government-sponsored NIEM (National Information Exchange Model) standard. The NIEM is developed by the Department of Justice and Homeland Security, and has been adopted by courts nationwide. The CourtTrax data model is comprised of both a subset of standard NIEM data components and, where necessary, new components added by CourtTrax in compliance with NIEM extension guidelines.
The model provides substantial value to our clients as they consume our data: (1) data semantics are defined right along with the document structure in the XML schemas, (2) the normalized model is consistent from court to court, dramatically increasing data usefulness, while also lowering the barrier of entry to new court jurisdictions by maximizing client code reuse, and (3) localized subset views of the model are supplied to clarify for client developers which portions of the model are in play in each jurisdiction.